
競馬予測での機械学習の利用(1)

–はじめに–
この記事は、実際に機械学習を使った中でも一番最初に手を付けた題材である競馬の着順予測について、どのように扱ってきたのかを紹介するものになります。もっといいアプローチができただろうと思うこともあるかもしれませんが、何もわからない状態から始めたということでご容赦頂きたいと思います。また、ここでは、競馬の仕様の調査(データの分析)から仮説を立てるまでの経緯をお話させていただくことにします。
また、この記事では、以下の用語を使うことが多いので、ここであらかじめ定義しておきます。
競馬に関する用語
新馬戦:一度も出走したことのない馬が走るレース
走破能力:馬毎に過去のレースのタイム、距離等から走る能力として算出した値。
回収率:投資に対するリターンの割合
適合率:全予測結果に対し、正解であった割合
logloss:確率の精度を計る指標、0に近いほど正確な確率
目次
1.目標設定
そもそも、「競馬」とは何か、と考えてみると「ギャンブル」の一つです。

「大数の法則」により、確率は収束していくので、「ギャンブル」でお金を稼いでいこうと思うと、「期待値が+のものにだけ賭ける」ことが重要になってきます。今回、自分達も、競馬で稼ぐこと自体は目的ではありませんが、稼げるラインを目標値として機械学習の研究を進めていくことにしました。
競馬も、他のギャンブルと同様、「期待値」が存在するはずです。ただし、確率が公表されている(=期待値が計算できる)パチスロ・宝くじ等と違い、競馬の場合はまず確率がわかりません。よって、競馬では「確率から期待値を求める」ことが難しいので、「統計的判断」により期待値を算出する他ないと考えます。すなわち、「この買い方でのトータル回収率が110%だった」という結果から、「今後も同様の買い方を続けていけばトータルの回収率は110%になるはず」というような形です。この「過去のトータル回収率」である110%というのを期待値だと考えます。
1-1を踏まえて、まずは目標として、馬券種不問で、トータル回収率120%という設定をしました。
この目標を設定したときは、機械学習を使えば回収率100%くらいならすぐ超えるだろうなどと甘く考えていました。しかし、実際にやってみると100%を超えるのも難しい現実がありました。
単勝(1位になると予測される一頭の馬に賭ける)馬券の還元率は80%で、これより高い還元率の馬券はないようです。すなわち、還元率の高い単勝馬券でも、普通に買っていると、回収率が80%ということになります。回収率100%というとこれと20%の差しかありません。しかしこの20%を上げるのは容易ではありませんでした。
たかが20%、されど20%。さて、この20%の差とはどのくらいなのでしょうか?その回収率の差のイメージを持っていただけるよう、1レース、1日、1年それぞれの単位での回収率毎の期待収支を表にしてみました。
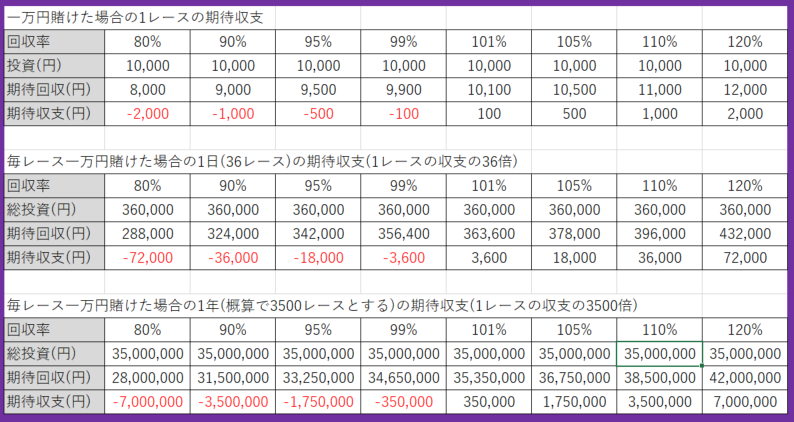
こうして見ると、20%の差というのは一回のレースで1万円賭け続けると、期待値レベルで、年間700万もの差が出ることがわかります。20%というのは意外と大きいと思いました。
最初は、「人間が予測できない部分を予測できる」ことが機械学習の強みであると考えました。よって、人間の予測の集合と言ってもいいオッズについてはデータとして機械学習に与えず、着順予測をメインに行うことにしました。
一番人気をずっと買い続けると33%くらいの確率で単勝が当たるとのことで、まずは1着の予測精度も適合率33%くらいを目指しました。ただ、やはり生き物のやることなので、絶対はあり得ません。着順そのものをいくら予測しようとも、100%に近い精度で着順を当てることはできないでしょう。よって、特定の着順になる確率も求まった方が良いと考えます。
以上から、精度を測る指標として、適合率とloglossを用いました。
2.アプローチ
PDCAの前に、まずは競馬そのものについて、また、そのデータについて知らないことが多かったため、分析用のDBを構築しています。このDBは、自分達が「競馬」というものの仕様を理解するためでもあるので、冗長性を極力省き、正規化をしています。
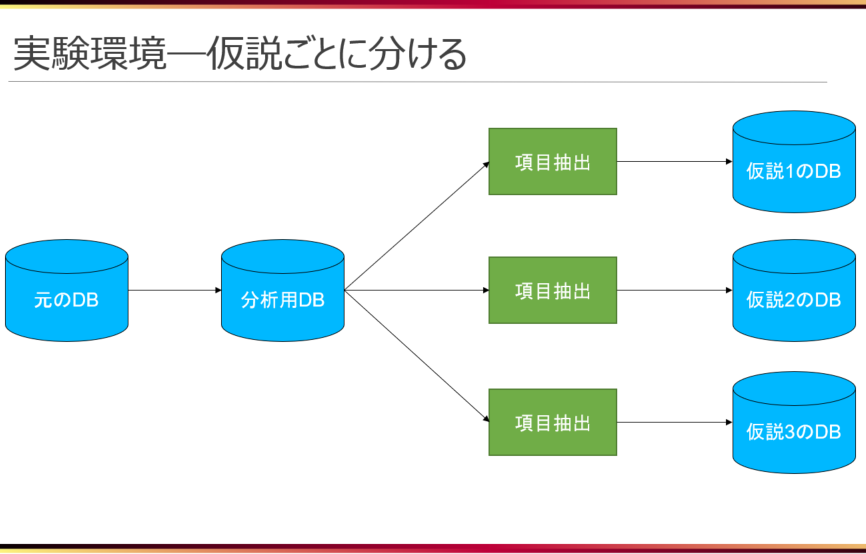
「機械学習を扱う心構え」の記事でもお話させて頂いたように、機械学習を扱う上では、二種類のPDCAサイクルを回す必要があります。その中でも、データ改良のPDCAに関しては、過去の実験で用いたデータと比較検証するために過去に生成したデータも保持しておく必要があると考えました。このデータ保持にあたり、各実験のデータを同じ環境に置いてしまうと混乱すると考え、ルールに基づいて整理することにしました。具体的には、以下のように、仮説に基づいたデータ毎に環境を分ける形です。
機械学習を使うための物理的なアプローチについては2-1で述べましたが、競馬の予測そのものへのアプローチとして、まずは競馬の仕様を理解する必要があります。私自身、馬券の種類やオッズの存在はなんとなく知っていました。しかし、馬がどんなコースを走るのか、出走できるのは何頭までなのか、等知らないことも多いのが実情でした。このままでは機械学習にどんな情報を与えるべきか見当もつきません。
そこで、いきなりデータを見るだけではよくわからないので、2-1にも書いたように自分達の手で分析用のDBを構築することにしました。これを構築する過程で、実際のデータを見ながらその意味を理解していく形で、調査していきました。これにより得た競馬の仕様についての詳しい説明は、ここでは省略させていただき、必要に応じて、注釈を入れておきます。
この調査をある程度のところで終了とし、それまでで分かったことを元に、一旦は、学習・予測(検証)対象レースを以下の条件で絞り込みました。この時点では、まだ実際のレースが始まる前のデータには手を付けず、結果の分かっているレースのみで検証を行う、ということに留めました。
・新馬戦は除く
・レース開催年を1995以降に絞る
・地方競馬については考慮せず、中央競馬のみを対象とする
・結果の出ているレースに絞る
・障害レースを除く
この後に、実際にデータを加工したり、実験を行う中で気づいた欠損値や異常値なども多数存在しますが、大きく影響のあるものについては、追い追い紹介していこうと思います。
3.仮説を立てる
前提として、「機械学習が扱えるデータの条件」を満たす必要があります。今回は着順という答えが存在する「競馬」が題材なので、教師あり学習で扱うデータの条件を満たせばよいということになります。
しかし、最初の段階では、機械学習に対する知見も浅かったため、実際に扱う機械学習のモデルの条件はもう少し厳しいものとなりました。以下にまとめておきます。
■今回のモデルで扱うデータの条件
・データ数が一定量ある(学習に十分と思われるデータ量)
・数値データである
・INPUTの要素数が一定
・OUTPUTの要素数が一定
これらの条件を念頭に置き、どんな情報を与えるべきか、を考えていきます。
「INPUT、OUTPUTの要素数が一定」という条件を考えると、「出走頭数がレース毎に異なる」ということから、レース単位での学習、予測は難しいと判断し、「レースに出走する一頭の馬(以降、出走馬と呼ぶ)」という単位で学習、予測することにしました。
それぞれの出走馬について「勝った馬は強い(速い)」という考えの下、「過去の戦績」をこれからのレースを予測する元のデータとすることにしました。過去の戦績と言っても、出走馬毎に「過去何回走ったのか」は異なります。よって、過去の戦績をそのまま持たせるのではなく、それをそれぞれの出走馬について集計&加工したものを入力データとしました。
先に述べたように、機械学習に与えるデータは、INPUT、OUTPUT双方について、要素数が一定でなければなりません。これは、学習時と予測時という関係でも同様であり、「学習時のINPUTは過去のレース情報ないけど、予測時は過去の情報から計算しよう」ということはできません。よって、学習の際に与える過去レースの情報についても、それぞれのレース時から見て過去となるレースの情報を集計するということになります。
3-1で、出走馬単位のデータで学習、予測を行うことを決めました。しかし、これにより新たな問題が発生しました。出走馬単位のデータを扱うということは、「同じレースに出走する他の馬との関係がわからない」ということになります。
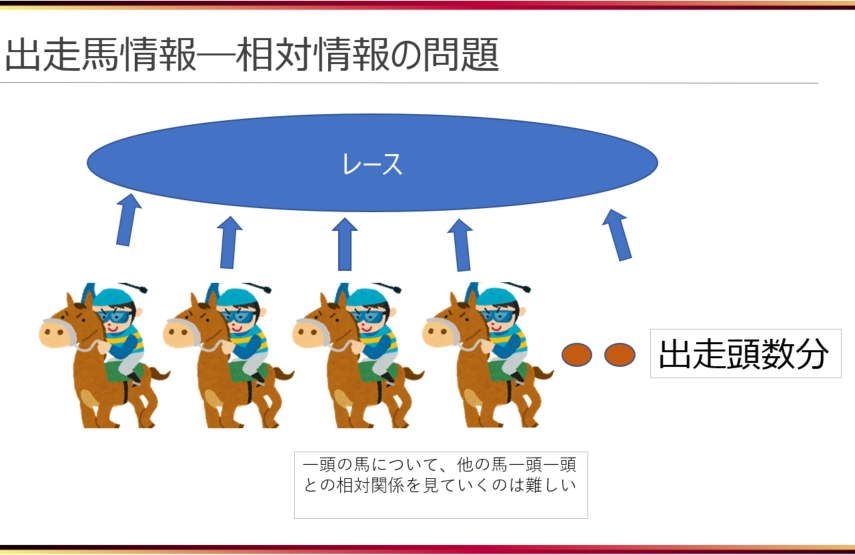
これでは、周りと比べられないので、着順も何もわかりません。そこで、各馬について、レース内での相対的な位置は、「レース全体から見てどのレベルにいるのか」が分かればよいと判断しました。そして、それぞれのレースについて、出走する全馬の走破能力の最大、最小、平均をレースの相対情報として出走馬の情報に加えました。これをレースのレベル感(下図で特定レベルと言っているもの)を測る指標として与えることで、着順予測をすることにしました。
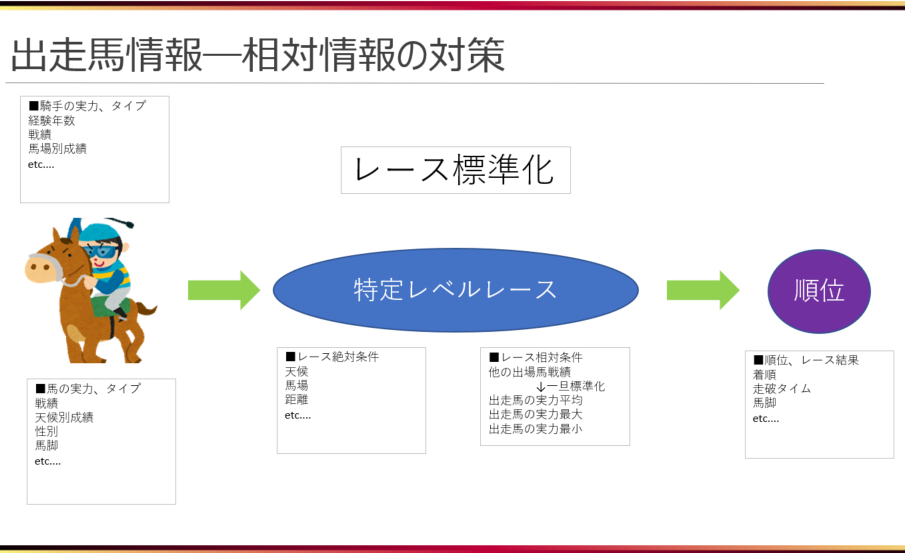
血統やコースについては、数値化するのが難しいので、今回は見送ることにしました。騎手についても、当初は入力情報として扱う予定でしたが、いきなり多くの情報を考えるのは難しいだろうと判断し、馬の実力(=馬の過去のレース結果とした)とレース(コース)の状態(芝、ダート、天候、距離等)のみに着目し、それらを入力情報としました。
具体的にどのデータをどのように用意したかについては、次の記事でお話するつもりです。
春から秋にかけてはほぼ毎日アニメTシャツを着ている
趣味は二次元の女の子を愛でること
「可愛いは正義」という信念に基づき、可愛いものを守るために日々奔走している



