
GDBを使って物語を要約してみる

はじめに
インターン生の齋藤です。
社内の物語要約コンテストにGDBを用いた手法で挑戦してみました。
今回はその概要を説明しようと思います。
GDBとは?
GDBとはグラフデータベース(Graph Data Base)の略であり、ノードとエッジ(点と線)で構成されたデータベースのことです。
GDBのサービスの一つにneo4jがあり、以下の画像はブラウザ上でGDBを可視化したものです。
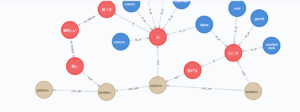
テーブルで構成されるリレーショナルデータベースと比べると、「各点同士の関係が分かりやすい」「新しい関係を付け足すことが簡単」などの良い点があります。
この他にもGDBは「A君の友達の友達の友達は、、?」のような深い関係の検索を高速で行えるという特徴を持ちます。
しかし、この特徴は今回活かせず、ただ関係性を操作しやすいデータベースとしての活用に留まりました。
PythonでGDBを使う
今回、GDBはPythonでNeo4jを動かすことで作成しています。
書いたコードでは、以下のようにstory_gdbというclassを定義しました。
(url、username、passwordにはそれぞれNeo4jのURL、登録したユーザー名、パスワードを代入しています)
|
1 2 3 4 5 6 7 |
from neo4jrestclient import client from neo4jrestclient.client import GraphDatabase class story_gdb: def __init__(self,url,username,password): #グラフデータベースの初期化を行う self.gdb = GraphDatabase(url,username = username,password = password) |
以下のようなコードを実行するとGDBにノードやエッジを追加できます
|
1 2 3 |
n_dict["sentence0"] = gdb.nodes.create(name = "sentence0") n_dict["sentence0"].labels.add("sentence") n_dict["sentence0"].relationships.create("next_sen",n_dict["sentence1"+],senNo = 0) |
今回はPythonの辞書型でgdbで作成したノードを管理できるようにしました。
辞書型でノードを管理するとこの後の経路探索などの時に便利です。
このあたりの詳細はneo4jのリファレンスを参考にしてください。
又、クエリを直接打ち込むことによりGDBの編集を行うことも可能です。
今回の手法概要
今回は物語の要約ということで、文脈の把握をするために、
①類似概念をまとめる ②頻度以外でキーワードを評価する ③時系列を考慮する
ことを目標としてアルゴリズムを考案しました。
具体的には、
①文章を要約文章作成用のGDBに落とし込む
②各ノードのスコアをLexRankによって計算した上で経路探索する
という流れで出力を得ました。
要約文章作成用のGDB構成
自然言語処理ライブラリのGiNZAを利用して、形態素解析・構文解析を行ったものをGDBに落とし込みました。
(GiNZAのGithubページ:https://megagonlabs.github.io/ginza/)
この時に
・同じ英単語に翻訳される単語をつなぐ(①類似概念をまとめる)
・時系列をエッジで管理する(③時系列を考慮する)
・文章の頭にノードを追加する(不要な文章をスキップさせる目的)
などの点を考慮してデータベースを作成しました。
その結果、例えば「石ころを投げた。石を食べたらおいしくなかった。」という文章を表示すると先ほどの図のようになります。
・「石」と「石ころ」という似た概念が”rock”でつながっている
・時系列を考慮しているため、矢印の通りにノードを辿ると大体意味が分かる
・文章の最初と最後にsentenceの名前のノードが存在する
ことが分かると思います。
ここでは、動詞は全て動詞の原形で表示するようにして、活用は各エッジに格納するようにしています(残念ながら上の画像では表示されていないのですが)。
これにより、1つの動詞に対して1つのスコアをつけることや、時系列ごとに動詞の活用をとることができるようになります。
ノードのスコア計算・経路探索を行う
物語では重要な単語は物語内に散らばって存在すると考えたので、各ノードのスコアはPageRankと併せて文章内での分散の値を計算して平均をそろえて算出しました。これにより、特に伏線回収のような文脈に注目できます(②頻度以外でキーワードを評価する)。
経路探索については、強化学習の状態価値評価を参考に、離れるにつれて将来のスコアが割り引かれるようなモデルを考案しました。
結果
例としてシンデレラの物語を入力すると
。行く事はできませんでした。舞踏会どんな女性何処女性は誰だろうとささやきあっていましたがトレメイン夫人は何処の誰だか確かめない侭時ガラスの靴片一方のガラスの靴が合う女性事を王子様が御ふれを知るなりましたがなる大公様。片一方のガラスの靴はぴったり。王子様とシンデレラし再会し結婚式を挙げました。仲良しの動物達は二人を見送るのでした。
のような出力が返ってきました。
問題点
・GiNZAからGDBに落とし込みきれていない
GDBへの落とし込みが上手く出来ていないために文法が滅茶苦茶になってしまう部分があります。今回は経路を辿って出力を行うため、再現性が低くなってしまうという問題もあります。
・経路探索アルゴリズムが不完全
今回、経路探索で扱うノード数が大きすぎる問題などにより、全ノードについて時系列を考慮した経路探索アルゴリズムは実装・検証しきれませんでした。
・文章が短くならない
一番最初のノードと一番最後のノードを辿る最大スコアの経路を探索する手法なので、要約と言えるまで文章が短くなりきらない場合があります。
今後の展望
今回は文脈把握にあたっての3つの目標をうまくアルゴリズムで表現することが出来ませんでした。
今後、日本語の文章構造に最適化したGDBへの落とし込み、経路探索アルゴリズムの効率化を行うことにより、より精度の高い要約文が生成されるのではないかと思います。
この記事のタグ
機械学習や統計の分野に興味がある。
最近の趣味はYouTubeでバッティング理論の勉強をすること。



