
競馬予測での機械学習の利用(2)

–はじめに–
この記事は前の記事「競馬予測での機械学習の利用(1)」の続きという位置づけになります。ですので、まだ読んでない方は先にそちらを読んでいただくよう、お願いします。前の記事やそれに付随する内容については、知っていることを前提として話を進めさせていただきます。ご了承ください。
この記事では、具体的にどのようなデータを用意し、どのようなアルゴリズムを用いて予測を行ったのか、ということをお話させていただきます。
目次
1.データ用意
前回の記事で、「目標設定」から「仮説を立てる」ところまでを紹介させていただきました。この章では、仮説を立てた後の設計から、機械学習に与えるデータを作成するところまでを紹介します。
INPUTデータを作ろうにも、どんな種類のデータを特徴として与えるか、を決めなければ、データの作りようがありません。よって、まずはINPUTデータをどう定義したのか、を話していきます。
前回の記事の「仮説」では、「レース」と「馬」のみに着目するというお話をしましたが、具体的には以下のように整理しました。
■レース:
・相対条件
・絶対条件の中でも固定のもの
・絶対条件の中でも変化するもの
■馬の実力:
・マスタ(固定情報)
・実力(経歴)
・当該レース時のみの状態
実際に定義したデータは以下になります。

結果も含まれているので、全てINPUTデータというのも少し語弊がありますが、教師データとして機械学習に与えるINPUTということで、ご容赦ください。また、最初はもっと多いデータを定義していましたが、最初から全てやろうとすると難しいので、まずはこれらのデータでやってみようということになりました。
さて、1.1にてデータの定義について述べました。しかし、馬の過去の戦績や、年齢、出走間隔ピークなどについて、どのような数値を与えるべきなのか、を統計的に判断する必要があります。よって、上の図で定義してしまっているものもありますが、簡単に分析を行いました。
馬の過去の戦績(走破能力)のバイアス値については、
・短距離(1600m以下):1000
・長距離(1600m以上):(全馬の短距離レース結果の平均速度/全馬の長距離レース結果の平均速度)×1000
というように、算出しました。特に意味はないのですが、テーブル定義を整数型にしたかったため、小数点以下3桁までを有効数字とし、短距離のバイアス値は基準として1000にしました。一番最初の実験を行う前にはこれくらいしか数値の算出は行いませんでした。
出走間隔や年齢については、詳しい分析を行う必要があったので、数値を算出し、INPUTデータとして追加するのが、少し遅れることとなりました。
年齢については、レース毎に年齢の条件があり、分析に時間がかかるので、この記事で紹介する実験の段階では、年齢をそのまま与える形となりました。出走間隔については、後に紹介するPDCAを繰り返す間に取り入れることができました。
出走間隔は、3~4週間がピークで、5週間目からの下がり具合がすごかったです。また、これらの項目をINPUTとして与える意味があるのか、という点についても裏付けを取るため、統計的な観点から分析を行いました。この部分については一つ一つ取り上げてもキリがないので、割愛させていただきます。具体的には、以下のように、相関係数や偏差値などを算出し、それらの関係性を分析していました。
※以下、出走間隔の例
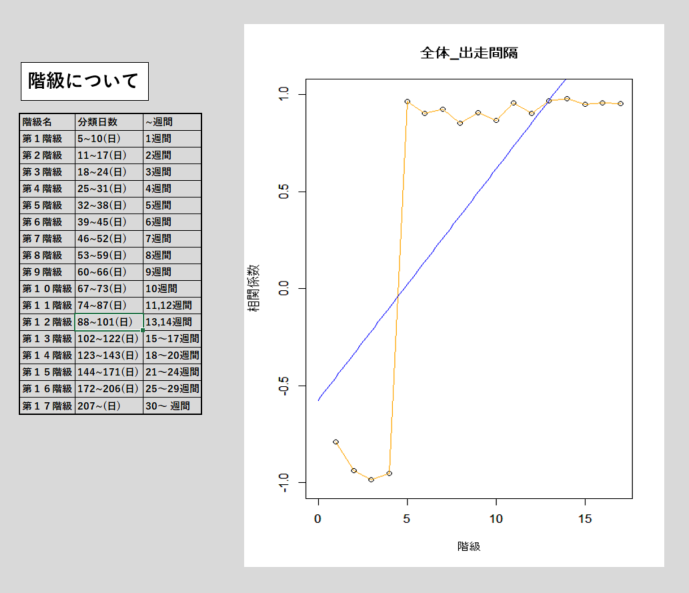

データの定義、データを作るための簡単な分析をした後、機械学習で扱うDBテーブルを作るための設計に取り掛かりました。この時点では、まだ年齢や出走間隔について、どんなデータを与えれば良いかわからなかったので、年齢については年齢そのままの数値とし、出走間隔のデータは作りませんでした。
前回の記事でお話したように、実験環境毎にDBスキーマを分けており、今回は最初の実験になるので、実験環境1(以後、exp1と呼ぶ)として作りました。
機械学習に与えるデータをいきなり作ろうと思っても、諸々の計算をする必要があり、分析用DBからそのまますぐに作れる状態ではありませんでした。よって、まずは分析用DBから計算に必要なデータを移行し、そのうえで、どのように計算して結果を集積するのか、という仕組みの部分の設計、構築を行いました。
この部分については、自分達のDBに関する知見が浅かったので、DBのプロにご助力いただき、何とか作り上げることができました。機械学習を扱う上で、DBを扱えないと、ほとんど何もできないに等しいと感じました。
2.実験
さて、データの用意ができたのでいよいよ機械学習アルゴリズムを使うときが来ました。アルゴリズムについて、ここまであまり触れて来ませんでしたが、実は、データ用意と並行してアルゴリズムの調査も行っていました。最初は、機械学習アルゴリズムに関する知識が浅く、漠然とどんなものがあるのかを知っている、という程度でどんなことができるのかもよくわかりませんでした。
そんな中で、汎用性が高そうだということで
・ニューラルネットワーク
・遺伝的アルゴリズム
の二つを中心に調査を進めました。
また、使用言語は、機械学習ライブラリが豊富でプログラミング初心者にもわかりやすいPythonにしました。
競馬のデータセットが用意できた段階では、機械学習アルゴリズムの調査は大きくは進んでおらず、とりあえずはTensorflowのニューラルネットワークを使って着順予測を行うことにしました。
いきなり一着の着順予測を行うのは厳しいと考え、以下二つの指標で精度を評価することにしました。
・3着以内の適合率
・loglossの値(低い方が優れている)
最初は、一から自分でアルゴリズムを組むのが難しく、「Tensorflowを使ったディープラーニングでタイタニックの生存予測」という記事を元にコードを作成しました。もちろん、参考記事のコードをそのまま使っても(馬だけに)うまく動かないので、諸々修正する必要があり、修正していく中でコードについては学んでいきました。多少の変更は加えましたが、最初の実験の段階では、基本的に参考記事のコードに準じた形になりました。
実験におけるPDCAはデータのPDCA、アルゴリズムのPDCAの二つがありますが、アルゴリズムの方は、今後の馬記事で詳しく取り上げていく予定ですので、それらに関してはここでは割愛します。
INPUTデータの欠損値や異常値については、本来、データを用意するまでに取り除く、標準化する等なにかしらの対策を取る必要があるのですが、実験を行っていく中での発見もいくつもありました。例を挙げると、出走しているのにタイムや着順が0であったり、体重が0kgや999kgなどがありました。このように、学習に悪影響を与えるようなデータが存在しており、それらの対処をするためにDBを作り直すということも多々ありました。これらの問題について、なぜそのような値が入ってしまっているのか、という原因を探り、そこから対策を考える必要がありました。タイムの例では、出走しても、途中で落馬したり、コースから出て行ってしまい、そもそもゴールしない場合もあると考え、そういったレースを無視するという対策を取りました。
他にも、アルゴリズム側で、DBで用意された値が大きすぎるとその項目の影響を強く受けてしまったりするという問題が生じました。また、機械学習に与える数値については、標準化した値の方が良いということで、項目ごとに標準化した値を持たせたテーブルを作成したり、他の馬との差分のみを持たせたテーブルを作成したりしました。それらについては、バージョンを振って管理するようにしました。
ここまで、データの用意からアルゴリズムの構築、PDCAを回すお話をしてきました。通常、結果と言えば一回の実験の結果を指すと思いますが、ここでは、PDCAを何度も回した総合的な結果からお話させていただきます。
結論から言いますと、予想外に結果は悪かったです。3着以内の適合率でありながら、どのモデルも適合率が20%台という状態でした。これは単勝1番人気の1着適合率である30%よりも低い値であり、とても信じられませんでした。
結果としては、散々なものでしたが、最初からそんなうまくいくほど世の中は甘くないと思い知らされました。
ここまで精度が悪かったことの原因は、データとアルゴリズム双方にあるとは思いますが、このexp1のデータを用いたいろいろなモデルの成果がこの結果と考えると、やはりデータを改良しないことには大きな精度向上は望めないと思いました。
問題点として、以下のようなことが挙げられます。
・騎手に関するデータがない
・馬やレースの情報も充足していない
・機械学習に与える数値が適切でない
これらについて改良したことについては、また後の記事でお話していこうと思います。
3.まとめ
最初の実験は散々な結果になりましたが、学べたことは多かったです。適合率を上げ、人間の精度(単勝1番人気の1着確率)を超えることは難しいと思いました。
この後、機械学習が「人間には予測できないものを予測できる」と考え、回収率を上げることも行っていきました。回収率を馬券種の組み合わせで上げることも考えましたが、それは機械学習の本質を追及する上ではコストパフォーマンスがあまりよくないと判断し、単勝馬券での回収率のみに留めました。その中でのPDCAが実質的にはメインでしたが、それらについては、今後、紹介していきたいと思います。
ここまで読んでいただき、ありがとうございました。
春から秋にかけてはほぼ毎日アニメTシャツを着ている
趣味は二次元の女の子を愛でること
「可愛いは正義」という信念に基づき、可愛いものを守るために日々奔走している



