
機械学習を扱う心構え

はじめに
この記事は、「機械学習の入門」の続きという位置付けになっています。よって
・機械学習って何?
・機械学習はどんなことに使われているの?
というようなことは、↑のリンクから「機械学習の入門」のページへ移っていただければと思います。
この記事は、機械学習にこれから取り組もうという段階で
・機械学習ってどんな仕組み?
・機械学習の何が大変なの?
・機械学習を使ってみようと思うけどどこから手を付けていいかわからない
といったような疑問を持つ人に向けて書いたつもりです。
前の記事に書いてあるように、「機械学習における学習とは、予測、分類モデルの最適化を指す」ということを前提とします。この記事では、その「学習」の仕組みの話から始め、機械学習を扱う際のポイントとして、何を理解する必要があるのか、どんな手順で学習、予測、検証するのか、などについて記載していきたいと思います。
機械学習アルゴリズムの数式の解説のような詳しいお話は出てきません。
自分も勉強中の身なのでまだまだ未熟です。これは違うんじゃないか、ここはおかしい、そうじゃない、というところがあればご指摘頂けると幸いです。この記事については、自分の学んできたことから書いており、内容については主観的判断を含みます。
この記事の目次
- 機械学習はどのように学習しているのか?
├1-1.教師あり学習
├1-2.教師なし学習
└1-3.強化学習 - 機械学習を扱うポイント
├2-1.機械学習の本質とは?
├2-2.機械学習を扱う手順
└2-3.なぜ本質を追求すべきなのか? - まとめ
1.機械学習はどのように学習しているのか?
前の記事でも触れた教師あり学習、教師なし学習、強化学習それぞれの学習手法について、どのように学習(計算式を更新し最適化)していくか、ということについて少し掘り下げていこうと思います。
教師あり学習における学習(計算式の最適化)は以下のような流れで行われています。
学習についてのみの説明になりますので、検証については、図に含めておりませんが、教師あり学習では、最初に全データを訓練データセットとテストデータセットに分けるという工程を挟みます。学習に用いるのは訓練データセットのみなので、図中ではテストデータを含めていません。
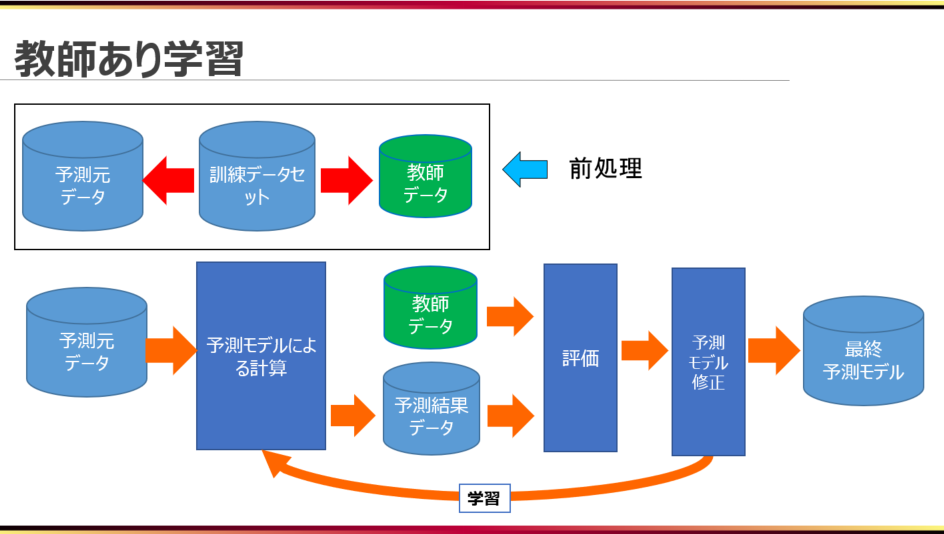
まず最初に、前処理として、訓練データセットを予測元データと教師データに分けます。
それから、予測元データを入力として予測モデル(計算式)に与え、計算を行い、予測をします。
そして、予測結果のデータ(予測モデルによる出力)と教師データ(正解となる出力)との誤差を評価し、誤差が最小になるように予測モデルを修正していきます。
この予測→評価→修正という流れを一定回繰り返すことで、予測元データと出力データの関係性を適切に表す予測モデルが出来上がります。
教師なし学習における学習(計算式の最適化)は以下のような流れで行われます。
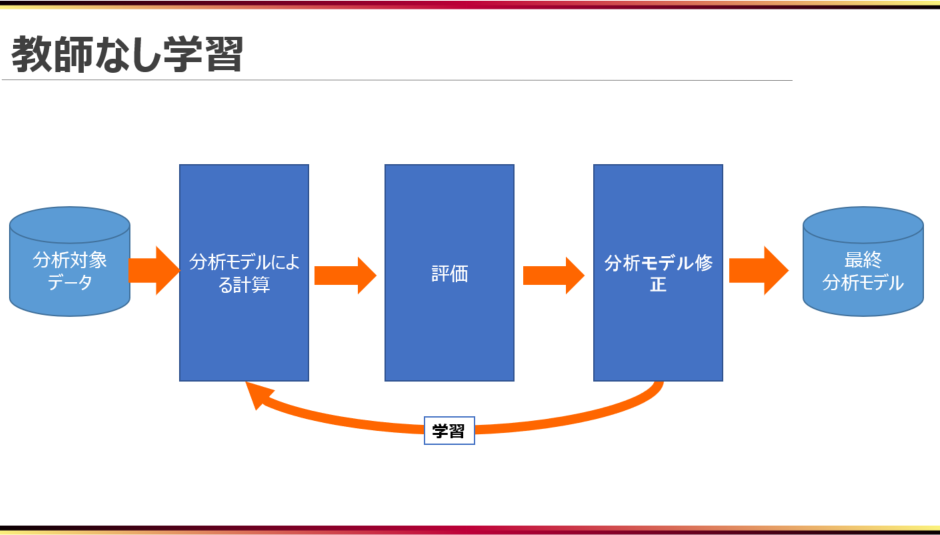
まず、分析対象のデータを分析モデル(計算式)に与え、計算を行い、それらのデータ間の類似度等を算出します。
そして、それらのデータ同士の関係性を評価し、評価値が最小、最大、一定量などになるように分析モデルを修正していきます。
これを一定回繰り返すことで、分析対象データの関係性を適切に表す分析モデルが出来上がります。
※前の記事にもあるように、教師なし学習では出力が存在しません。
強化学習における学習(計算式の最適化)は以下のような流れで行われます。
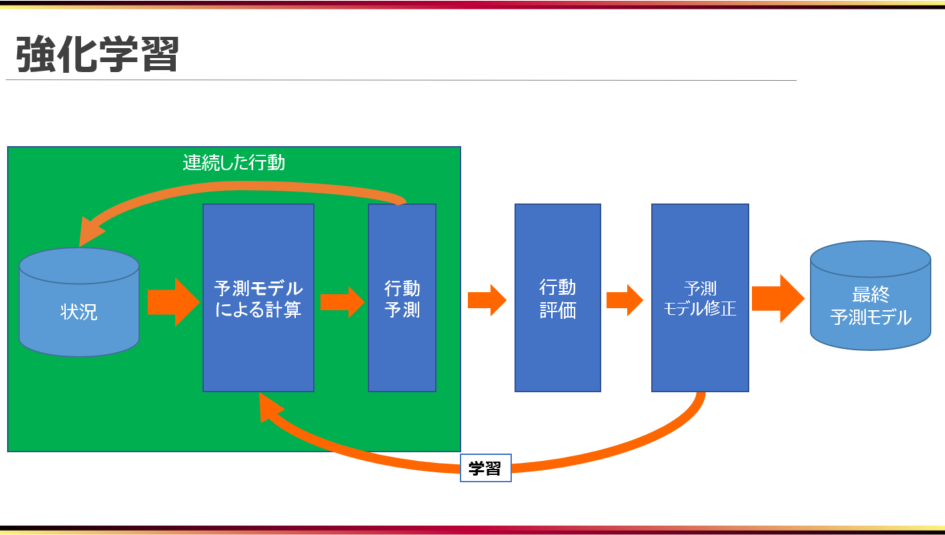
まず、最初の状態をデータとして予測モデル(計算式)に与え、計算を行い、行動を決定します(行動予測)。
行動の結果、状態が変わり、その状態をデータとして予測モデルに与えます。
これを繰り返し、定めた評価タイミング(囲碁や将棋、オセロなどの二人零和有限確定完全情報ゲームでは、勝ち負けが決まったタイミングにする等)で評価を行います。
そして、連続した行動の結果を評価し、評価値が最小、最大などになるように予測モデルを修正していきます。
これを一定回繰り返すことで、それぞれの状態に応じた適切な行動を選択する予測モデルが出来上がります。
以上1-1から1-3までの3通りの手法についてどのようにモデルを最適化していくよう学習するか、についてお話しましたが、どれも何かしらの評価値を元にモデル修正を行っているという点で同じことをしているとも見なせると思います。従ってこの記事では、これらの評価値を算出する関数を「評価関数」と呼ぶことにします。
2.機械学習を扱うポイント
機械学習を扱うポイントを一言で言ってしまうと
本質を追求していく
という姿勢で取り組むことだと考えます。
と言われても、機械学習の本質って何のこっちゃ???という疑問が浮かぶと思うので、まずはその本質とは何かということからお話させていただこうと思います。
機械学習の本質とは何なのでしょうか?
簡単に言ってしまうと、
機械学習の中身の計算式
だと考えています。
本質を追求していく上で以下のような数学的知識が要求されます
①線形代数
・機械学習アルゴリズムによる計算では、行列やベクトルを扱うことが多いです。
→実際にどのような計算をしているのか、を知るためには必須と言えます。
②確率・統計
・機械学習はそもそも統計の延長であり、あるデータセットの法則性を見出すものです。
→統計的観点は必須となります。
・機械学習の計算式に扱われていることも多いです。教師あり学習における精度などは確率そのものなので、誤差も確率を用いて計算することが多くなります。最尤推定法などはその典型ですね。
③微分・積分
・機械学習では評価関数の最大、最小値を求めることが多いです。すなわち、微分して0になることを目指すことが多くなります。特に(評価関数に含まれる「予測、分析モデルの更新対象パラメータ」について)偏微分を扱うことが多いです。
※以下は具体例になります。数式とその説明になるので、読みたくない方は↓をクリックお願いします。
実際にこれらの数学的知識がどのように使われているのでしょうか?その例として、下の図ではニューラルネットワークという機械学習アルゴリズムで使われている逆誤差伝播法(計算モデルの更新式)という手法を取り上げてみました。偏微分している個所を赤い丸で囲ってあります。
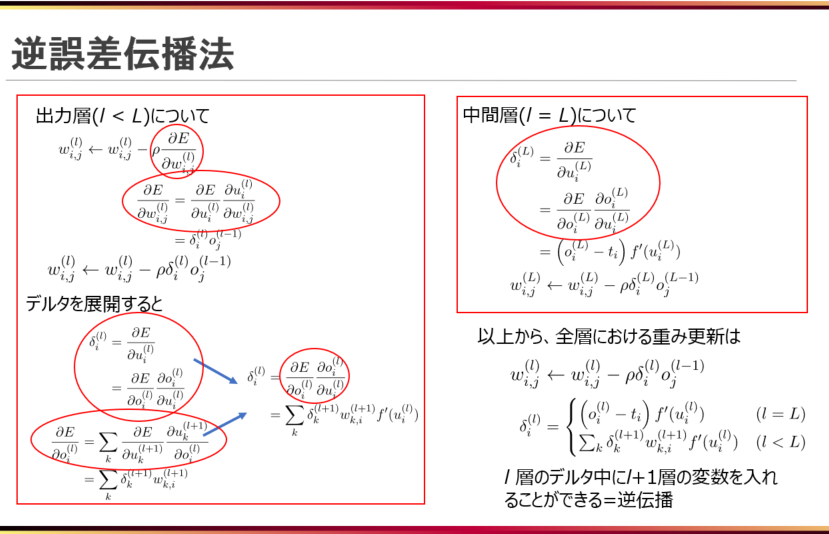
このように、機械学習は実際にさまざまなところで数学と密接に関わっています。
この記事では上の図の一つ一つのパラメータについての説明などはしません。詳しい説明は「ニューラルネットワークの基礎」の記事に掲載してあります。
前の節で機械学習の本質とは何か、ということについて説明させていただきました。
しかし、なぜ本質を追及する必要があるのか、という疑問があることと思います。
その疑問にお答えする前に、まずはその前提となる「機械学習を扱う手順」についてお話させていただこうと思います。
機械学習を扱ってみると、最初の検証で目的を達成することはほぼないと言えます。従って、目的の達成に向けた精度向上が必要になり、その過程でデータ改良とアルゴリズム改良という二つのPDCAを繰り返すことになります。
下の図は、そのPDCAを繰り返す実験フローを図示したものであり、二つのPDCAはそれぞれ赤のサイクルと緑のサイクルで表しています。この部分について詳しくは、説明の都合上、次節にてお話することとし、本節では、それぞれがどのようなフェイズかという説明に留めておきます。
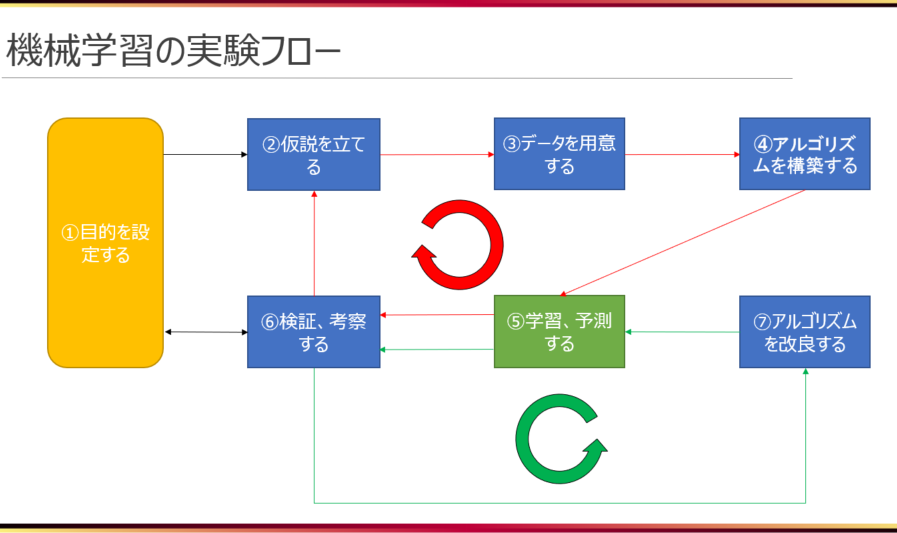
①目的を設定する・・・まずは目的の設定が必要です。何を満たせば良しとするかを設定するフェイズです。競馬の例を挙げると、「着順予測精度が40%を超える」や「単勝馬券回収率100%を超える」等になります。
②仮説を立てる・・・目的を達成する上で必要な情報は何か、ということについて仮説を立てるフェイズです。競馬の例を挙げると、「勝った馬は強い=過去の戦績が必要」や「親が強ければ子も強い=血統の情報が必要」等になります。さらに細かく、戦績と言っても「タイムの情報」、「距離」、「天候」、等様々あり、そこから選択していきます。
③データを用意する・・・仮説に基づいて、必要な情報を数値データのセットとして用意するフェイズです。
④アルゴリズムを構築する・・・機械学習アルゴリズムを選択し、ロジックを組むフェイズです。(※厳密には、機械学習アルゴリズムの選択によって、用意するデータの数値や種類の変更を行うこともある。)
⑤学習、予測する・・・④で作成したアルゴリズムに学習をさせ、出来上がったモデルを用いて予測を行うフェイズです。
⑥検証、考察する・・・①で設定した目的を達成しているのか、を検証して考察するフェイズです。例えば、競馬の例ばかりで飽きるかもしれませんが競馬で「単勝馬券回収率100%」を目的として定めた場合、検証結果が90%だったとします。考察として、「過去の戦績の着順をデータとして与えてなかったから」や「アルゴリズムの更新に用いた評価関数の式が不適切だった」等を挙げていくことになります。
⑦アルゴリズムを改良する・・・アルゴリズムの中身のパラメータや数式の変更、アルゴリズムそのものの再選択、追加、削除などを行うフェイズです。
2-2でお話したようなPDCAサイクルを回す行為は、繰り返しになるので工数が嵩む部分になります。闇雲に総当たりのようなことをするにもいかないので、それらのPDCAの部分についてはよく理解しておかなければいけません。これらの理解をするために、本質を追及すべきであると考えています。このことについて、2-2の手順を踏まえた上で、説明していきたいと思います。
機械学習を扱うということは、2-2の手順で紹介した2つのPDCAを回すということとほぼ同義になるので、データとアルゴリズムの2つについての理解が大変重要になってきます。まずは、この2つのPDCAについて、説明させていただきます。また、機械学習の本質の理解が必要なポイントについては太字で表現しています。
■データの改良について
■大量データの用意・・・機械が正しく学習を行える十分なデータ量が必要ですが、これはアルゴリズムやハイパーパラメータ(※1)にも依存します。例として、前の記事でも触れられていることですが、深層学習では、予測モデルで修正する対象の変数が多いので、通常のニューラルネットワーク等よりも多くのデータが必要ということがあります。
■データの種類の決定・・・仮説を立て、影響を与えそうな情報を入力データ種別として決定していきます。この時点でどんな情報を与えるかによって以降の工程で何をしてもダメ、なんてことになるのは日常茶飯事なので、ここの影響が一番大きいです。極端な例では、競馬の着順予測をしたいのに、アイスクリーム屋の売り上げに関する情報をいくら与えても、なかなかうまくいかないというようなことです。
■データの形の決定・・・機械学習は数値型しか扱えません。また、入力データも出力データも、学習に与える要素数を変えて学習することはできません。競馬の例を挙げると、レース毎に出走頭数が異なる場合、レース単位でデータを与えることはできません。そして、同じデータ(情報)でもアルゴリズムによってどんな数値にして与えるべきか、は変わってきます。例えば、カテゴリカルデータ(区分値)について、ニューラルネットワークでは「一つの情報をそれぞれのカテゴリ(区分)に分けて当てはまるカテゴリにのみ1を立て、他は0を入れる」方が良いのに対し、遺伝的アルゴリズムでは「カテゴリカルデータをそのまま与える」方が良いということがあります。
■データの分布、値の大きさの設定・・・アルゴリズムによって、学習の際に扱う数値のばらつき具合や、大きさが変わってきます。例として、ニューラルネットワークを扱う際、前処理として、一つ一つの情報について、数値を正規化するという手法が使われていることもあるようです。
■検証・・・データの検証は、アルゴリズムに与える前に全て検証し、与えるデータに欠損値や異常値が含まれていない状態にするのが理想です。しかし現実には、アルゴリズムに与えた結果出てきた出力を見て気づくこともあります。
■データ修正・・・「データの種類」と「データの形」の双方において、何がどういけなかったのか考察し、新たに仮説を立てる、最適と思われるデータの形へ変換するなどして、再度データを用意していきます。
■アルゴリズムの改良について
■アルゴリズムの選択・・・回帰なのか分類なのか、教師ありなのか教師なしなのか、強化学習なのか、等によって扱うアルゴリズムを選択します。例えば、私の知る範囲の話ではありますが、ニューラルネットワークでは、分類が得意で回帰は苦手という特徴があります。
■ハイパーパラメータ(※1)の調整・・・評価関数はどんなものを設定して、学習で扱う更新式は何で、データ量はどのくらいで一回の学習でどの程度更新するのか、何回学習するのか、等を設定します。
■検証・・・過学習(※2)は起きていないか、精度は十分か、等を検証します。訓練データの精度は良いのに対し、テストデータの精度は悪いと過学習が起きていると判断できます。精度については、目的を満たしているのか、目的まではどのくらい足りないのか、を確認します。
■アルゴリズムの改良・・・過学習や、計算が正常に行えない等の問題が起きたとき、原因を突き止め、改良する必要があります。また、精度が十分でない場合、アルゴリズムについては、学習に用い評価関数やモデルの更新式、等について考察、改良していきます。この際、アルゴリズムの内部の関数の変更、組み込み、削除を行う必要があります。
※1:ハイパーパラメータ・・・一度の学習に使用するデータ数、学習回数等、機械学習アルゴリズムによって学習されない、人間の手で設定する必要があるパラメータです。
※2:過学習・・・訓練データに過度に対応してしまう現象です。詳しくは後の記事で説明していく予定です。
3.まとめ
いかがでしたでしょうか?機械学習における「学習」の仕組みはどんなものか、機械学習を扱う上でどんなことが大事なのか、ということが少しでも伝わっていたら嬉しいです。
簡単にそれぞれの要点をまとめておくと
・機械学習における学習(=予測、分析モデルの最適化)とは、評価値をより良くする方向に計算式を修正することである
・機械学習を扱うということはデータとアルゴリズムそれぞれについてのPDCAサイクルを回して精度向上を図るということである
・機械学習の精度向上には中身の計算式の理解が不可欠であり、その理解には大学レベルの数学的知識が求められる
ということになります。
機械学習アルゴリズムで扱われている詳しい数式レベルのお話は別記事にて書く予定ですので、そちらもぜひ見て頂きたいです。
自分もまだまだわからないこともあり、あくまで主観的に書かせて頂いている部分もありますので、「それはちがうよ!(CV:緒方〇美)」というところなどありましたらコメントいただけると嬉しいです。
前の記事
春から秋にかけてはほぼ毎日アニメTシャツを着ている
趣味は二次元の女の子を愛でること
「可愛いは正義」という信念に基づき、可愛いものを守るために日々奔走している



